はじめに
数万行あるExcelやCSVデータを使って、データの集計を行うのに、全てExcelを用いているとPC側のスペックの問題で作業が効率的でないことがよくあります。特に、データ集計・分析にあたっては、データクレンジングを含めて、下準備が必要であることも多く、 pythonのpandasを使った方が効率的であることがあります。
今回含めて複数に分けて、pythonのpandasを用いたコーディングの方法や、用いることが可能な引数をまとめていきます。
※ 本稿では、ライブラリのインポート方法や開発環境の整備については割愛し具体のコードのみ、個人的な備忘として整理していきます。
データ集計・分析の全体像(本稿の位置づけ)
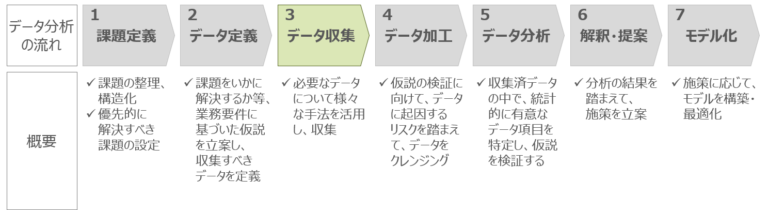
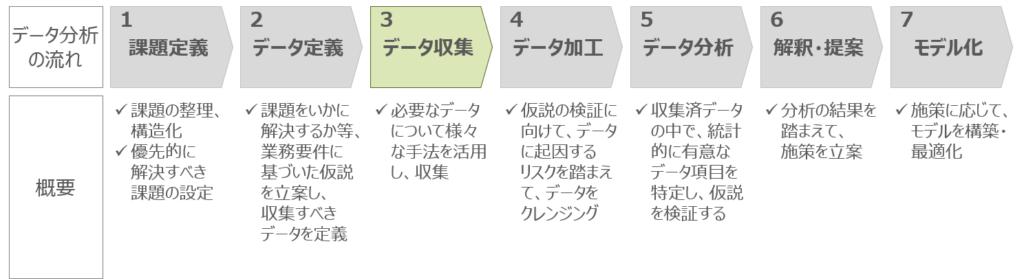
工藤卓哉、保科学世著「データサイエンス超入門」によれば、データ分析の流れは大きく7ステップあると言及されています。
データの読込み方法
Excelファイルである場合
(コードテンプレート)
import pandas as pd
データフレーム名 = pd.read_excel(ファイルパス, sheet_name=シート名 ,header=0, usecols=[列名1, 列名2, 列名3], dtype={列名1:object})
| 項目名 | 設定内容 |
| ファイルパス | 読み込むファイルの絶対/相対パスを設定。 |
| sheet_name | 読込みたいExcelシートを設定することで、特定シート読込みが可能。 |
| header | 開始行が1行目ではない場合等に、読み込みたい開始行を設定。 |
| usecols | 使いたい列が特定されている場合に設定。 複数列を設定するにあたっては、「[]」で囲む必要有。 |
| dtype | データ列のデータ型を指定して、読込みたい場合に設定。 この場合、ある列を○○の型で読み込みたいという形になるので、Dic型のように「{}」で囲む必要有。 |
CSVファイルである場合
(コードテンプレート)
import pandas as pd
データフレーム名 = pd.read_csv(ファイルパス, header=0, usecols=[列名1, 列名2, 列名3], dtype={列名1:object}, encoding=’cp932′)
| 項目名 | 設定内容 |
| ファイルパス | 読み込むファイルの絶対/相対パスを設定。 |
| header | 開始行が1行目ではない場合等に、読み込みたい開始行を設定。 |
| usecols | 使いたい列が特定されている場合に設定。 複数列を設定するにあたっては、「[]」で囲む必要有。 |
| dtype | データ列のデータ型を指定して、読込みたい場合に設定。 この場合、ある列を○○の型で読み込みたいという形になるので、Dic型のように「{}」で囲む必要有。 |
| encoding | 文字コードを指定したい場合に設定。 「sjis」や「cp932」があるが、個人的にエラーが出た際には「cp932」を設定することが効果的な印象。 |
最後に
個人的にも、いつもコーディングするときに忘れてしまいがちなことをまとめてます。今後は、データクレンジング(ある値で空白を埋める、データ変換、列名変更等)の方法を一気にまとめていきたいところです。
必要に応じて追記していきますので、もし「これも!」ってものがあれば、ご教示いただけますと幸いです。