はじめに
これまでに、pythonを用いたExcelファイルやCSVファイルの読込み方法について、こちらでまとめました。
自分がプログラミングする際に使った関数を今後の備忘を兼ねて、引き続き整理していきます。
データ集計・分析の全体像(本稿の位置づけ)
工藤卓哉、保科学世著「データサイエンス超入門」によれば、データ分析の流れは大きく7ステップあると言及されています。
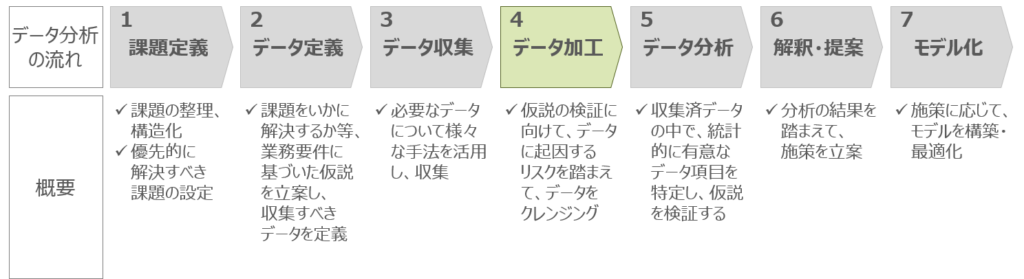
データの分析においては、「大多数がデータクレンジングに費やされる」といわれるほど、重要なプロセスになります。システムから出されるログファイルでない場合(手入力でのExcelファイル等)には、特に本プロセスでいかにデータを綺麗化できるかが、後のプロセスを円滑に進めるための鍵となります。
データクレンジングの方法
データ型の確認
(コードテンプレート)
データフレーム.dtypes
データクレンジングにおいては、読み込んだデータフレーム(仮想のExcelファイルみたいなもの)上のデータ型を確認することが重要ですが、上記コードで列ごとのデータ型を確認できます。
型変換(文字列から日付型)
(コードテンプレート)
import pandas as pd
変換後の series 型 = pd.to_datetime(変換前の series 型, errors=’coerce’)
| 項目名 | 設定内容 |
| errors | データによっては、文字列に変換したい列に、それ以外の値が入っていてエラーになる場合があります。 「coerce」を指定しておくことによって、変換できないものは「NaT」にしてくれるため、エラー発生を抑えることができます。 |
| format | 標準的な形であれば自動変換してくれますが、特殊なデータにおいては【format=’%m月%d日’】のように、指定した形で変換することが可能です。 |
その他、formatと併用して【.apply(lambda x: x.replace(year=2020))】のように、特殊な加工を行う場合もありますが、本項では説明を割愛します。あくまで基本形を全量整理ことが目的のため。
型変換(文字列から数値、数値から文字列等)
(コードテンプレート)
import pandas as pd
変換後の series 型 = 変換前の series 型.astype(int)
変換後の series 型 = 変換前の series 型.astype(str)
このコードは特に引数を指定するものではないため、追加説明は割愛します。
値の置き換え
(コードテンプレート)
import pandas as pd
対象データフレーム.replace ({‘列名1’ : {‘置換前の値1′:’ 置換後の値1′,’置換前の値2′:’置換後の値2′}, ‘列名2’:{ ‘置換前の値3′:’置換後の値3′,’置換前の値4′:’置換後の値4’}}, inplace=True)
あまり推奨はされていないのですが、inplaceをTrueにしておくと、置換前のデータフレームの値を完全に置き換えることができます。なお、複数の値を置換する場合は、Dict型を扱うときのような書き方が必要であることに注意。
重複行の削除
(コードテンプレート)
import pandas as pd
対象データフレーム.drop_duplicates(subset=’基準列’, keep=False, inplace=True)
| 項目名 | 設定内容 |
| subset | 重複行を削除するかどうかを確認する列を指定。 |
| keep | 重複した行のいずれを削除するかで設定が異なる。 ‘first’であれば、最初の行が削除されず、’last’であれば最後の行が削除されることになる。 重複行全てを削除したい場合は、Falseを指定する。 |
なお、他のものと同様に、inplaceをTrueにしておくと、置換前のデータフレームの値を完全に置き換えることができます。(前述の通りアラートが表示されます。)
不要行/列の削除
(コードテンプレート)
import pandas as pd
対象データフレーム.drop (columns=[‘列名1′,’列名2’], axis=1, inplace=True)
列の場合は上記となりますが、行を削除したい場合は「columns」を「index」に変更し、引数axisを「0」にします。
空白値を埋める/空白値がある行を削除する
数値が入っているデータフレームで計算等を実施したい場合に、空白となっている行を削除したり、特定の値が埋めたい場合があります。まず、0で埋めたい場合のサンプルコードは以下。もし、他の値で埋めたい場合は、0を他の値に書き換えればOKです。
(コードテンプレート)
import pandas as pd
対象の列名1( series 型).fillna (0, inplace=True)
空白値がある行を削除したい場合のサンプルコードは以下。
(コードテンプレート)
import pandas as pd
対象データフレーム.dropna(subset=[‘ 列名1 ‘,’ 列名2 ‘], inplace=True)
対象列が複数ある場合は、上記のように囲う必要があることに留意。
Dataframeの結合
(コードテンプレート)
結合後のデータフレーム = pd.merge (データフレーム1, データフレーム2 , on=’結合判定列’, how=’left’)
| 項目名 | 設定内容 |
| on | 結合するキーとなるデータが入っている列を指定します。 共通する列が存在しない場合、【left_on=”キー1″】及び【right_on=”キー2″】でラベルを指定します。 |
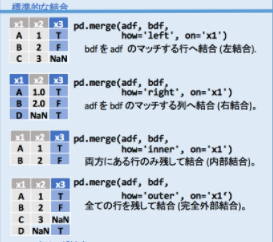
| how | 結合方法を指定します。 サンプルの「left」以外にも、「inner」や「outer」、「right」があります。 |
結合方法については、Githubにあるチートシート(https://qiita.com/s_katagiri/items/4cd7dee37aae7a1e1fc0)がとても分かりやすいため、そちらを引用します。
最後に
結構端的に書いたつもりですが、意外と長文になってしまいました。。それだけ、クレンジングに関しては色々な処理を行っているということかなと。
いっつも忘れるやつを含めて、よく使うものをまとめたため、必要に応じてご活用くださいませ。